Structured Text > Migrating content to Structured Text
The objective of this guide is to teach you how to migrate an existing DatoCMS project to Structured Text fields. To illustrate the process, we'll use an example project that you can clone on your account to follow each step.
Note: If you prefer to skip the tutorial and just take a look at the final code, head over to this Github repo.
High-level strategy & Project skeleton
This is the content schema of the project:

The fields we want to convert into Structured Text are the following:
HTML Article > Content (HTML multi-paragraph text);
Markdown Article > Content (Markdown multi-paragraph text);
Modular Content Article > Content (Modular content);
To do that, we're going to write three migration scripts (one for each model) and test the result inside a sandbox environment.
For every field, the high-level plan will be the same:
Create a new Structured Text field for the model;
For every article, take the old content, convert it to Structured Text and save it in the new field;
Destroy the old field.
Let's open the terminal, create a new directory for the migration project, and install the DatoCMS CLI:
mkdir structured-text-migrationscd structured-text-migrationsnpm init --yesnpm install --save-dev datocms-clientmkdir -p migrations/utils
Inside the migrations/utils directory we're adding some functions that we're going to use for all three migrations:
createStructuredTextFieldFromcreates a new Structured Text field with the same label and API key as an existing field, but prefixed withstructured_text_(basically, step 1 of our plan);getAllRecordsfetches all the records of a specific model using thenestedoption, so that for modular content fields we get the full payload of the inner block records instead of just their ID (that's the first bit of step 2);swapFieldsdestroys the old field, and renames the new Structured Text field as the old one (that's step 3 of our plan);
Lastly, since:
some API calls expect the model ID and not the model API key, and
model IDs are different on each environment, and
we want our migrations to work on any environment
we can avoid hardcoding model IDs writing a getModelIdsByApiKey function that returns an object mapping API keys to Models IDs:
// ./migrations/utils/createStructuredTextFieldFrom.jsmodule.exports = async function createStructuredTextFieldFrom(client,modelApiKey,fieldApiKey,modelBlockIds) {const legacyField = await client.fields.find(`${modelApiKey}::${fieldApiKey}`);const newApiKey = `structured_text_${fieldApiKey}`;const label = `${legacyField.label} (Structured-text)`;console.log(`Creating ${modelApiKey}::${newApiKey}`);return client.fields.create(modelApiKey, {label,apiKey: newApiKey,fieldType: "structured_text",fieldset: legacyField.fieldset,validators: {structuredTextBlocks: {itemTypes: modelBlockIds,},structuredTextLinks: { itemTypes: [] },},});};// ./migrations/utils/getAllRecords.jsmodule.exports = async function getAllRecords(client, modelApiKey) {const records = await client.items.all({filter: { type: modelApiKey },nested: 'true',},{ allPages: 30 },);return records;};// ./migrations/utils/swapFields.jsmodule.exports = async function swapFields(client,modelApiKey,fieldApiKey) {const oldField = await client.fields.find(`${modelApiKey}::${fieldApiKey}`);const newField = await client.fields.find(`${modelApiKey}::structured_text_${fieldApiKey}`,);await client.fields.destroy(oldField.id);await client.fields.update(newField.id, {apiKey: fieldApiKey,label: oldField.label,position: oldField.position,});};// ./migrations/utils/getModelIdsByApiKey.jsmodule.exports = async function getModelIdsByApiKey(client) {return (await client.itemTypes.all()).reduce((acc, it) => ({ ...acc, [it.apiKey]: it.id }),{},);};
Migrating HTML content
Let's create the first migration script:
> dato new migration convertHtmlArticlesCreated migrations/1612281851_convertHtmlArticles.js
Then replace the content of the file with the following skeleton, which uses the utilities we just created:
// ./migrations/1612281851_convertHtmlArticles.jsconst getModelIdsByApiKey = require('./utils/getModelIdsByApiKey');const createStructuredTextFieldFrom = require('./utils/createStructuredTextFieldFrom');const getAllRecords = require('./utils/getAllRecords');const swapFields = require('./utils/swapFields');module.exports = async (client) => {const modelIds = await getModelIdsByApiKey(client);await createStructuredTextFieldFrom(client,'html_article','content',[modelIds.image_block.id]);const records = await getAllRecords(client, 'html_article');for (const record of records) {await client.items.update(record.id, {structuredTextContent: await htmlToStructuredText(record.content),});if (record.meta.status !== 'draft') {await client.items.publish(record.id);}}await swapFields(client, 'html_article', 'content');};
A couple of notes:
Inside the HTML field there might be image tags (
<img />). Structured Text does not have a specific node to handle images because it offersblocknodes, which is a more powerful primitive. This means that, during the transformation process, we'll need to convert those<img />tags into block records of type "Image" (that's the same block currently used by the Modular Content field). For this reason, in line 15 we pass theimage_blockmodel ID to configure the newly created Structured Text field to accept such types blocks;Lines 20-22 is where we're going to perform the actual records update;
Lines 24-26 make sure we republish updated records (unless they were in draft).
So what is left to do is to implement the htmlToStructuredText() function.
The datocms-html-to-structured-text package offers a parse5ToStructuredText function that is meant to be used in NodeJS environments to perform the conversion from HTML to Structured Text (parse5 is a popular HTML parser for NodeJS).
Internally, the parse5ToStructuredText will take the parse5 Document, convert it into a hast tree, and then convert the hast tree into a dast tree (that's the format of our Structured Text document). All these conversions might seem an overkill, but we will see later how having hast as an intermediate representation will come in handy.
Let's install some dependencies:
npm install parse5 \datocms-html-to-structured-text \datocms-structured-text-utils \unist-util-inspect \unist-utils-core
Now we have everything we need to build our htmlToStructuredText function:
// ./migrations/utils/htmlToStructuredText.jsconst parse5 = require("parse5");const { parse5ToStructuredText } = require("datocms-html-to-structured-text");const { validate } = require("datocms-structured-text-utils");const inspect = require("unist-util-inspect");module.exports = async function htmlToStructuredText(htmlContent, settings = {}) {const htmlDocument = parse5.parse(htmlContent);const structuredText = await parse5ToStructuredText(htmlDocument, settings);const validationResult = validate(structuredText);if (!validationResult.valid) {console.error(inspect(result));throw new Error(validationResult.message);}return result;}
Please note that in line 12 we use the validate function from the datocms-structured-text-utils package to make sure that the final result is valid Structured Text.
Converting image tags into blocks
The code above will convert 99% of the HTML correctly, but images present in the content will be skipped.
As we already noted before, that's because Structured Text does not have a specific node to handle images. Instead, it offers block nodes, which can handle images and much more. We have to pass some additional settings to the parse5ToStructuredText function to tell it how to convert <img /> tags to block nodes:
// ./migrations/1612281851_convertHtmlArticles.jsconst { buildModularBlock } = require('datocms-client');const { findAll } = require('unist-utils-core');module.exports = async (client) => {// ...the rest of the migration script stays the sameawait client.items.update(record.id, {structuredTextContent: await htmlToStructuredText(record.content, {preprocess: (tree) => {findAll(tree, (node, index, parent) => {// lift up img nodes up to the rootif (node.tagName === 'img') {tree.children.push(node);parent.children.splice(index, 1);return;}});},handlers: {img: async (createNode, node, context) => {const { src: url } = node.properties;const uploadPath = await client.createUploadPath(url);const upload = await client.uploads.create({ path: uploadPath });return createNode('block', {item: buildModularBlock({image: {uploadId: upload.id,},itemType: modelIds.image_block.id,}),});},},}),});}
A couple notes:
In line 22, we use the
handlersoption to specify how to convert the<img />hastnodes tags todastblocknodes (the default behaviour, as we saw, is to simply skip them);The
blocknode should contain a block record of type Image (that's the same block currently used by the Modular Content field), which in turn has a single-assetimagefield. In line 26-27 we create a new asset starting from thesrctag of the image, to feed it to theimagefield. Luckily, the handlers are async functions, so we can easily perform an asyncronous operation inside of it.Since in the
dastformat, ablocknode can only be at root level, we use thepreprocessoption (line 12) to tweak thehasttree and lift every image node up to the root (in case they're inside paragraphs or other tags).
We can test the migration with the following command from the Terminal, which will clone the primary environment into a sandbox, and run the migration:
dato migrate --destination=with-structured-text --token=<READWRITE_API_TOKEN>✔ Running 1612281851_convertHtmlArticles.js...Done!
Success! The article content is correctly converted to Structured text:


Migrating Markdown content
Once we know how to perform the HTML-to-Structured-Text conversion, we only have to do some minor changes to make it work also for Markdown content.
As we just saw, the datocms-html-to-structured-text package knows how to convert an hast tree (HTML) to a dast tree (Structured Text), so if we can convert a Markdown string to hast, then the rest of the code will be basically the same.
Luckily, hast is part of the unified ecosystem, which also includes:
an analogue specification for representing Markdown in a syntax tree called
mdast;a tool to convert Markdown strings to
mdast;a tool to convert
mdasttrees tohast.
Let's install all the packages we need:
npm install --save-dev unified remark-parse mdast-util-to-hast
We can now create a function similar to htmlToStructuredText called markdownToStructuredText that connects all the dots:
// ./migrations/utils/markdownToStructuredText.jsconst unified = require('unified');const toHast = require('mdast-util-to-hast');const parse = require('remark-parse');const { hastToStructuredText } = require('datocms-html-to-structured-text');const { validate } = require('datocms-structured-text-utils');const inspect = require('unist-util-inspect');module.exports = async function markdownToStructuredText(text, settings) {const mdastTree = unified().use(parse).parse(text);const hastTree = toHast(mdastTree);const result = await hastToStructuredText(hastTree, settings);const validationResult = validate(result);if (!validationResult.valid) {console.log(inspect(result));throw new Error(validationResult.message);}return result;};
We can now create the a new migration script:
> dato new migration convertMarkdownArticlesCreated migrations/1612340785_convertMarkdownArticles.js
And basically copy the previous migration, just replacing the name of the model (from html_article to markdown_article), and the call to htmlToStructuredText with a call to markdownToStructuredText:
// ./migrations/1612340785_convertMarkdownArticles.jsconst { buildModularBlock } = require("datocms-client");const { findAll } = require("unist-utils-core");const getModelIdsByApiKey = require("./utils/getModelIdsByApiKey");const createStructuredTextFieldFrom = require("./utils/createStructuredTextFieldFrom");const findOrCreateUploadWithUrl = require("./utils/findOrCreateUploadWithUrl");const markdownToStructuredText = require("./utils/markdownToStructuredText");const getAllRecords = require("./utils/getAllRecords");const swapFields = require("./utils/swapFields");module.exports = async (client) => {const modelIds = await getModelIdsByApiKey(client);await createStructuredTextFieldFrom(client, "markdown_article", "content", [modelIds.image_block.id,]);const records = await getAllRecords(client, "markdown_article");for (const record of records) {await client.items.update(record.id, {structuredTextContent: await markdownToStructuredText(record.content, {preprocess: (tree) => {findAll(tree, (node, index, parent) => {if (node.tagName === "img") {tree.children.push(node);parent.children.splice(index, 1);return;}});},handlers: {img: async (createNode, node, context) => {const { src: url } = node.properties;const uploadPath = await client.createUploadPath(url);const upload = await client.uploads.create({ path: uploadPath });return createNode("block", {item: buildModularBlock({image: {uploadId: upload.id,},itemType: modelIds.image_block.id,}),});},},}),});if (record.meta.status !== "draft") {console.log("Republish!");await client.items.publish(record.id);}}await swapFields(client, "markdown_article", "content");};
We can now run the new migration inside the sandbox environment we already created for the first migration:
> dato migrate --source=with-structured-text --inPlace --token=<READWRITE_API_TOKEN>✔ Running 1612340785_convertMarkdownArticles.js...Done!
Migrating Modular Content fields
To migrate Modular Content fields into Structured Text fields, we must acknowledge the fact that both fields allow nested record blocks: the difference between the two is that Modular Content is basically an array of record blocks, while in Structed Text record blocks are inside the dast tree in nodes of type block. In other words, our task here is, for every modular content, to transform an array of block records into a single dast document. It's up to us decide how to convert each block we encounter into one/many nodes into our dast document.
Let's take a look at the project schema again:
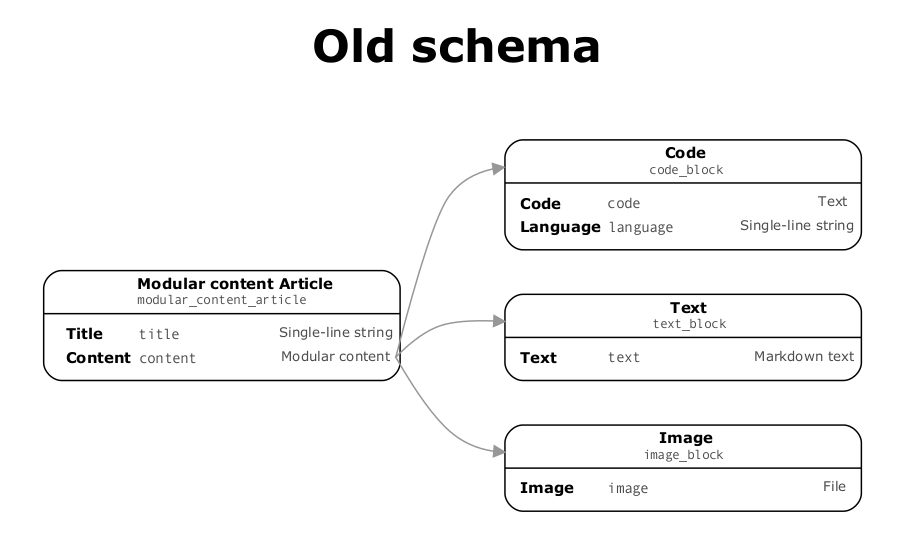
The existing Modular Content field supports three block types:
Text (which in turn contains a
textMarkdown field);Code (which has two fields, one that contains the actual code and another that stores the language);
Image (which, as we already know, it contains a single-asset field called
image).
Here's the code for our migration:
const { validate } = require("datocms-structured-text-utils");const getModelIdsByApiKey = require("./utils/getModelIdsByApiKey");const createStructuredTextFieldFrom = require("./utils/createStructuredTextFieldFrom");const getAllRecords = require("./utils/getAllRecords");const swapFields = require("./utils/swapFields");const markdownToStructuredText = require("./utils/markdownToStructuredText");module.exports = async (client) => {const modelIds = await getModelIdsByApiKey(client);await createStructuredTextFieldFrom(client,"modular_content_article","content",[modelIds.image_block.id]);const records = await getAllRecords(client, "modular_content_article");for (const record of records) {const rootNode = {type: "root",children: [],};for (const block of record.content) {switch (block.relationships.itemType.data.id) {case modelIds.text_block.id: {const markdownSt = await markdownToStructuredText(block.attributes.text);if (markdownSt) {rootNode.children = [...rootNode.children, ...markdownSt.document.children];}break;}case modelIds.code_block.id: {rootNode.children.push({type: "code",language: block.attributes.language,code: block.attributes.code,});break;}default: {delete block.id;delete block.meta;delete block.attributes.createdAt;delete block.attributes.updatedAt;rootNode.children.push({type: "block",item: block,});break;}}}const result = {schema: "dast",document: rootNode,};const validationResult = validate(result);if (!validationResult.valid) {console.log(inspect(result));throw new Error(validationResult.message);}await client.items.update(record.id, {structuredTextContent: result,});if (record.meta.status !== "draft") {await client.items.publish(record.id);}}await swapFields(client, "modular_content_article", "content");};
Every time we need to convert a Modular Content field, we start by creating an empty Dast root node (that is, one with no children, line 21-24).
Then, for every block contained in the modular content (line 26), we're going to accumulate children inside of the root node:
If it is a Text block (line 28), we use the
markdownToStructuredTextfunction to convert its Markdown content into a Dast tree, then take the children of the resultingrootnode and add them to our accumulator;Since Dast supports nodes of type
code, if we encounter a Code block (line 37), we simply convert it tocodenode, and add it to the accumulator;If we find an Image block (line 45), we'll wrap the block into a Dast
blocknode, and add it to the accumulator as it is.
Wrapping up
Once you get to know the Structured Text format, it becomes quite straightforward converting from/to its Dast tree representation of nodes, and the DatoCMS API, coupled with migrations/sandbox environments, makes it easy to perform any kind of treatment to your content.
You can download the final code from this Github repo.